
Agentic demos are easy. Operating agentic systems on-call is not.
When you move from “one impressive run” to “a workflow you can depend on,” the failure modes look familiar:
- action spaces explode,
- errors compound across long horizons,
- natural language becomes an implicit interface contract,
- policy becomes advisory instead of enforceable,
- and debugging turns into guesswork.
ARP exists because reliability is not a prompting problem. It’s a systems problem.
What is ARP?
ARP is an open, capability-oriented approach to building bounded, auditable agentic workflows.
ARP is intentionally three things:
- COP — Capability-Oriented Programming — a mindset for engineering around what a system can reliably do
- ARP Standard v1 — versioned API contracts and artifacts for portable execution
- JARVIS — a first-party open-source reference stack that runs the Standard end-to-end
If you only remember one line:
ARP turns “agents calling tools” into capability execution that is bounded, inspectable, and improvable.
What ARP is not
To avoid category confusion:
- ARP is not “another agent framework.”
- ARP does not standardize planner internals or “the best prompts.”
- ARP is not a hosted platform you must adopt wholesale.
- ARP is not just a tool catalog protocol.
ARP focuses on the layer that’s missing across most stacks: capability contracts + enforceable bounds + durable evidence.
The core idea: shrink decisions, keep evidence
ARP systems are built around two beliefs:
- If you want reliability, you must shrink the decision surface of the planner.
- If you want systems that improve, you must keep durable evidence of what happened.
That is why ARP makes these first-class:
- Capability contracts: explicit schemas + semantics
- Bounded candidate menus: the system chooses from a small approved set at each step
- Constraints + budgets: time, steps, cost, depth, branching, external calls
- Policy checkpoints: allow/deny/require-approval decisions tied to the run record
- Durable artifacts: events + inputs/outputs + decisions, designed for replay
How ARP works at a high level
ARP systems separate definition, selection, execution, and enforcement.
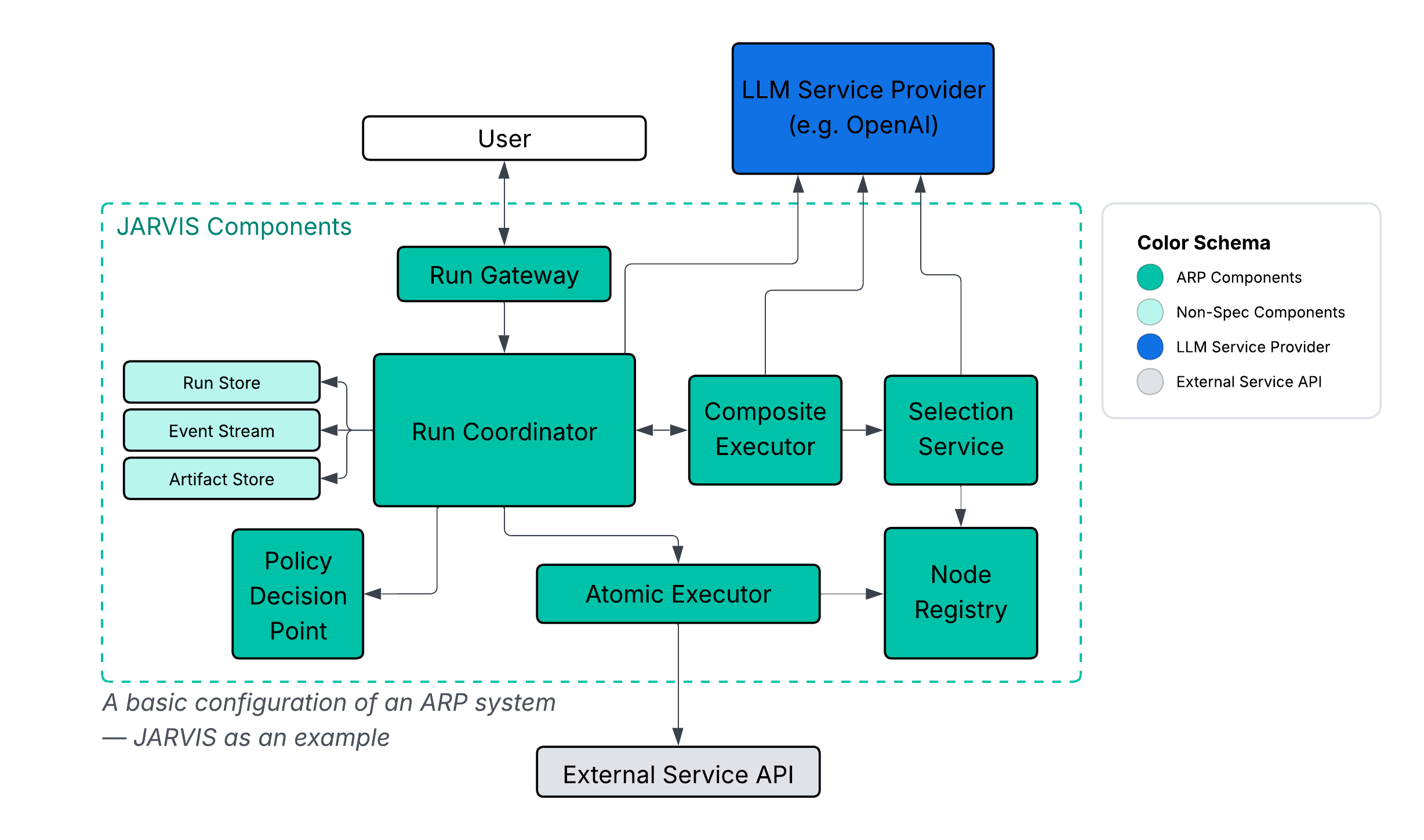
Key point: the coordinator is the enforcement anchor. Planners can suggest; the system enforces.
A concrete example in 60 seconds
Let’s say you’re building a support workflow. In ARP, you start with capabilities.
1) Define an atomic capability: contract + envelope
id: support.create_ticket
kind: atomic
input_schema:
type: object
required: [customer_id, issue_summary, priority]
output_schema:
type: object
required: [ticket_id, status]
semantics:
side_effect_class: write
idempotency: idempotent_by_key
constraints_defaults:
budgets:
max_wall_time_ms: 5000
max_external_calls: 2
evaluation:
success_criteria:
- ticket_id is present
- status in ["created", "queued"]2) For a subtask, produce a bounded candidate menu
Instead of giving the system “every possible action,” selection returns a bounded CandidateSet.
{
"candidate_set_id": "cs_01J...",
"subtask": "Open a support ticket with the customer and issue summary",
"top_k": 4,
"candidates": [
{ "node_type_id": "support.create_ticket", "score": 0.92 },
{ "node_type_id": "support.lookup_customer", "score": 0.71 },
{ "node_type_id": "support.search_similar_tickets", "score": 0.63 },
{ "node_type_id": "support.escalate_to_human", "score": 0.55 }
]
}3) Execute under explicit constraints and gates
{
"constraints": {
"structural": { "max_depth": 3, "max_total_nodes_per_run": 20 },
"candidates": { "allowed_node_type_ids": ["support.create_ticket", "support.escalate_to_human"] },
"budgets": { "max_wall_time_ms": 30000, "max_steps": 30 },
"gates": { "side_effect_class": "write" }
}
}4) Keep durable evidence
A run produces a durable timeline of “what happened and why”:
- what was decomposed,
- what candidates were allowed,
- what binding was chosen,
- what policy decision applied,
- what outputs were produced.
That evidence is what makes debugging and evaluation tractable.
Where to start
Pick your entry point:
What’s next
ARP is designed to get stronger as the ecosystem grows:
- richer evaluation scorecards attached to capability versions
- promotion/demotion gates so reuse is evidence-driven
- more policy semantics around approvals for irreversible actions
- deeper observability mappings into your existing telemetry systems
If you want to follow along, start with the launch series on the blog and the roadmap.
Next in the series: COP: Capability-Oriented Programming for production agentic systems